QA system 관련 논문 리뷰
2021. 12. 28. 20:55ㆍ논문리뷰
1. Overview of QA system
- QA(Question Answering) system: 자연어로 된 질문에 정확한 답을 하는 것을 목표로 함.
- 다양한 기준으로 QA system을 분류할 수 있음.
- IR_based_QuestionX의 경우, open domain 주제의 factoid/list questions에 대해 structured data인 knowledge base를 활용하여 answer를 도출.

1.1 Domain
1.1.1. Open Domain
- 특정 도메인에 국한되지 않고, 다양한 주제에 대해 질문/답변하는 시스템.
1.1.2. Closed Domain
- 특정 주제(예: 의료, 법률 등)에 대해 답변하는 질문/답변하는 시스템.
- 주로 전문적인 주제를 다루며, 제한된 정보를 취급하므로 답변의 질, 정확도가 open domain에 비해 높음.
1.2 Type of Questions
- question을 분류하는 방식은 다양함. 한 가지 예시를 가져옴.
1.2.1. Factoid type question
- 사실(fact)에 대한 질문으로, 정답의 개수가 1개(주로 named entity)인 경우. (영어의 경우 주로, what, when, which, who로 시작하는 질문)
- 예: 방탄소년단 멤버 중 광주 출신인 사람은?
1.2.2. List type question
- 정답의 개수가 여러 엔티티 또는 사실인 경우.
- 예: 공효진과 하정우가 함께 출연한 영화를 전부 알려줘.
1.2.3. Hypothetical type question
- 특정 상황을 가정하는 질문. (what would happen if ...?)
- 인공지능이 인간과 같은 감정을 느끼게 된다면 어떤 일이 벌어질까?
1.2.4. Causal type question
- 인과관계를 유추하는 질문.
- (특정 지문을 주고,) 민수가 마트에 간 이유는 무엇인가?
1.2.5. Confirmation type question
- Yes or No로 대답할 수 있는 질문
- 예: 맥북은 LG에서 만든 제품인가?
1.3 Data Sources
1.3.1. Structured
- 특정한 형식을 가진 데이터에서 정답을 찾는 경우.
- 예: RDF Graphs, SQL datbases, XML data
- RDF(Resource Description Framework) Graph: 노드와 엣지로 구성된 그래프 형태로 데이터를 저장하는 방법.
- knowledge graph 역시 RDF data.
- SPARQL(SPARQL Protocol And RDF Query Language): RDF로 저장된 데이터를 위한 표준 질의 언어. KBQA에서 많이 사용하는 쿼리.
1.3.2. Unstructured
- 특정한 형식을 가지지 않는 데이터에서 정답을 찾는 경우.
- 예: 위키피디아와 같은 plain text
2. Related keywords regarding IR_based_QuestionX
2.1 KB(Knowledge Based) QA
2.1.1. IR_based_QuestionX와의 관련성
- knowledge base에서 정답을 찾는다는 점에서 공통점을 가짐.
2.1.2. 설명
- "3.KB(Knowledge Based) QA"에서 자세히 설명.
2.2 IR(Information Retrieval) based QA
2.2.1. IR_based_QuestionX와의 관련성
- Elasticsearch와 같은 search engine을 사용하여 정보를 검색한다는 점에서 공통점을 가짐.
- 그러나 IR_based_QuestionX는 structured data인 KB를 인덱싱하여 검색하는 반면, IR based QA는 보통 plain text와 같은 unstructured data를 검색한다는 점에서 차이 존재.
- 따라서 쿼리와 관련성이 높은 문서를 검색하는 IR 단계와, 해당 문서에서 정답인 부분을 추출하는 answer extraction 단계로 구성됨. IR_based_QuestionX는 엔티티가 곧바로 정답이 된다는 면에서 별도로 문서 내에서 정보를 추출하는 과정은 필요하지 않음.
- 쿼리를 적절히 analyze하여 관련도 높은 문서를 잘 찾는 것이 중요한데 이 부분은, KB QA에도 적용되므로 "3.KB(Knowledge Based) QA"에서 해당 내용 다룸.
2.2.2. 설명

2.3 unsupervised QA
2.3.1. IR_based_QuestionX와의 관련성
- 학습데이터 없이 QA 모델링 한다는 점에서 공통점을 가짐.
2.3.2. 설명
- 학습 데이터를 만들어서 사용하는 방식
- annotated QA dataset을 사용하지 않고, 일반 문장들에서 엔티티를 마스킹하여 Question으로, 마스킹 된 엔티티를 Answer로 사용하여 QA모델 학습.
- 사전학습 된 임베딩을 사용하는 방식
- 사전학습된 GloVe 등의 임베딩 사용하여 질의 임베딩, 정답 후보 임베딩 구해서 질의와 정답 후보 사이의 유사도를 통해 정답 도출.
- 두 가지 모두 IR_based_QuestionX에는 적용이 어려움.
3. KB(Knowledge Based) QA
3.1 Approaches(survey 논문 2개에서 공통적으로 제시한 분류 방식 사용)
- A Survey on Complex Question Answering over Knowledge Base: Recent Advances and Challenges (2021)
- A Survey of Question Answering over Knowledge Graph (2019)
3.1.1. Information Retreival
- 질의에서 topic entity를 찾아, 이를 중심으로 subgraph를 추출. subgraph에 속하는 노드들이 정답 후보. 질의와 정답 후보 노드의 feature를 추출하여, 둘의 유사성을 바탕으로 정답을 예측하는 방식으로 학습.
저스틴 비버의 남자 형제가 누구야? -> '저스틴 비버'가 토픽 엔티티가 되고, 이와 연결된 subgraph 노드들이 정답 후보가 된다.

- feature engineering 방식: 직접 질의와 후보 노드의 feature를 정의하는 방식(manually defined and extracted features)
- Information Extraction over Structured Data: Question Answering with Freebase (2014)에서는 질의에 특정 단어가 주어졌을 때, 정답과 연결되는 엣지를 각 노드가 포함할 조건부 확률을 feature로 사용
- representation learning 방식: 질의를 넣고, 정답을 맞히는 과정에서 질의와 정답의 representation이 학습되게 하는 방식
- one-hop reasoning: 후보 노드의 피쳐를 1단계로 반영
- Bordes et al. : 정답 엔티티, 토픽엔티티와 정답 엔티티 사이의 relationship path, answer entity를 중심으로 한 subgraph의 세 가지 특징을 고려하여 정답 엔티티의 임베딩을 추출
- Dong et al. : Multi Convolutional neural networks(MCCNNs) -> Bordes el al.이 질의 벡터를 정답 노드에 관계 없이 단어의 합으로 추출하는 것과 달리, answer type, answer path, answer context(subgraph)에 따라 질의 노드를 다르게 임베딩하고 세 가지 임베딩을 합쳐서 질의 노드로 사용
- Hao et al. : 정답에 따른 질의 임베딩을 다르게 하되 그냥 합치는게 아니라 어텐션을 적용하여 상황에 따라 다른 부분이 강조되도록 함.
- multi-hop reasoning: 후보 노드의 피쳐를 1단계로 반영하는게 아니라, subgraph에서 subject, predicate, object로 이어져 정답 노드로 가는 순서를 반영
- Miller et al. : Key Value-Memory networks(KV-MemNN) -> 질의 임베딩 할 때, 질문 엔티티와 연결되는 subject와 predicate까지를 먼저 반영하고, 여기에 가중치를 두어 object 부분을 반영
- Qiu et al. : Stepwise Reasoning Network(SRN) -> 질의에 있는 엔티티로부터 정답 엔티티로 가는 path를 각 단계라고 보고 학습 진행
- one-hop reasoning: 후보 노드의 피쳐를 1단계로 반영
3.1.2. Semantic Parsing
- 자연어 질의를 해당 semantic을 잘 반영한 structured language인 SPARQL 등으로 변환하여 KB에서 정보 추출하는 모델.
- Query Graph 방식: 쿼리를 그래프 형식으로 바꾸어서 이것을 SPARQL로 변환
- Reddy et al. : GraphParser -> Combinatory Categorical Grammar(CCG)를 사용하여 질의 텍스트를 그래프로 변환
- Yih et al. : Staged Query Graph Generation (STAGG) -> GraphParser가 질의 텍스트를 그래프로 변환한 다음에 엔티티 링킹을 한다면, STAGG는 질의에서 엔티티 링킹을 먼저 진행하고 KB 내에서 해당 엔티티들을 연결할 수 있는 관계를 직접 찾아서 쿼리 그래프를 생성
- Encoder Decoder 방식: 쿼리를 인코더에 넣어서, SPARQL을 디코더에서 출력
- Template 활용 방식: SPARQL로 잘 변환 시킬 수 있는 질의 템플릿을 미리 만들어 놓고, 새로 질의가 들어왔을 때 가장 유사한 템플릿을 찾아서 매칭
- Query Graph 방식: 쿼리를 그래프 형식으로 바꾸어서 이것을 SPARQL로 변환
3.2 질의 전처리 및 데이터베이스 매핑 관련 기술
- Survey on Challenges of Question Answering in the Semantic Web (2017)
- Core Techniques of Question Answering Systems over Knowledge Bases: a Survey (2018)
3.2.1. Question Analysis: 자연어 질의에서 중요한 부분을 잘 analyze하는 것이 중요함
- Recognizing named entities
- Segmenting the question using POS tagging
- Identifying dependencies using parsers
3.2.2. Phrase Mapping: 자연어 질의에서 뽑아낸 phrase를 KB의 엔티티와 매핑
- Lexical Gap Problem
- 질의에서 사용된 단어가 KB에 존재하는 엔티티 라벨과 상이한 경우
- 예: 'sm엔터 소속 연예인 중 드라마 출연한 사람이 누구야?'라고 질문 했을 때, 자연어 질의에는 'sm엔터'라고 되어있지만 데이터베이스에는 'sm엔터테인먼트'라고 저장되어 있는 경우
- 해결 방안
- Knowledge base labels
- KB에서 엔티티 지칭하는 다양한 라벨 사용
- IR_based_QuestionX에서 사용하는 방식: '방탄소년단' 엔티티가 방탄, 방탄소년, 방탄소년단, bts 등 다양한 이름으로 저장되어 있어서 lexical gap이 크게 문제되지 않음.
- Dealing with string similarity
- 텍스트 유사도 함수 활용
- Dealing with semantic similarity
- semantic web 등의 데이터 베이스 이용해서 유의어까지 반영
- Knowledge base labels
3.2.3. Disambiguation: 매핑된 엔티티가 여러 개인 경우 질문의 의도에 부합하는 엔티티를 추려야함
- Ambiguity Problem
- 같은 phrase가 서로 다른 것을 의미하는 경우. 임베딩이 아닌 텍스트 기반으로 매칭시키는 경우, 같은 글자가 여러가지 의미를 가질 때 문제 발생.
- 예: 동음이의어(영화 장르가 드라마 / 영상의 형태가 드라마 -> 같은 드라마인데 다른 의미를 가짐)
- 해결 방안
- Local disambiguation
- Graph search
- Hidden Markov Model (HMM)
- Integer Linear Program (ILP)
- Markov Logic Network
- Structured perception
- User feedback
3.3 Keyword search over RDF (QA는 아님)
- 그래프 형식 데이터인 RDF에서, SPARQL이 아닌 Elasticsearch와 같은 document search engine을 통해 원하는 데이터 추출할 수 있는 방법에 대한 연구도 이루어지고 있음.
- Keywords Search over RDF Using Document-Centric Information Retrieval Systems (2020)
- 질의 타입, 필드 seperation(어떤 필드를 대상으로 검색할지), 필드 가중치(subject, predicate, object 중 어디에 가중치를 둘 것인지), similarity method에 따른 엔티티 검색 실험을 진행
- Elasticsearch 인덱싱을 사용하며, document 단위는 triplet (IR_based_QuestionX는 엔티티 단위로 document 저장)
- 어떤 경우에 원하는 엔티티가 가장 검색이 잘 되는지? * IR_based_QuestionX의 질문 형태인 Natural language questions의 경우, 검색 필드에 subject, predicate, object를 포함하고, subject와 predicate에 ^2의 가중치를 두고, BM25, LM Jelineck-Mercer similarity를 사용하는 경우 성능이 가장 높게 나타남.
- query type: 어떤 형태로 질의를 할지?
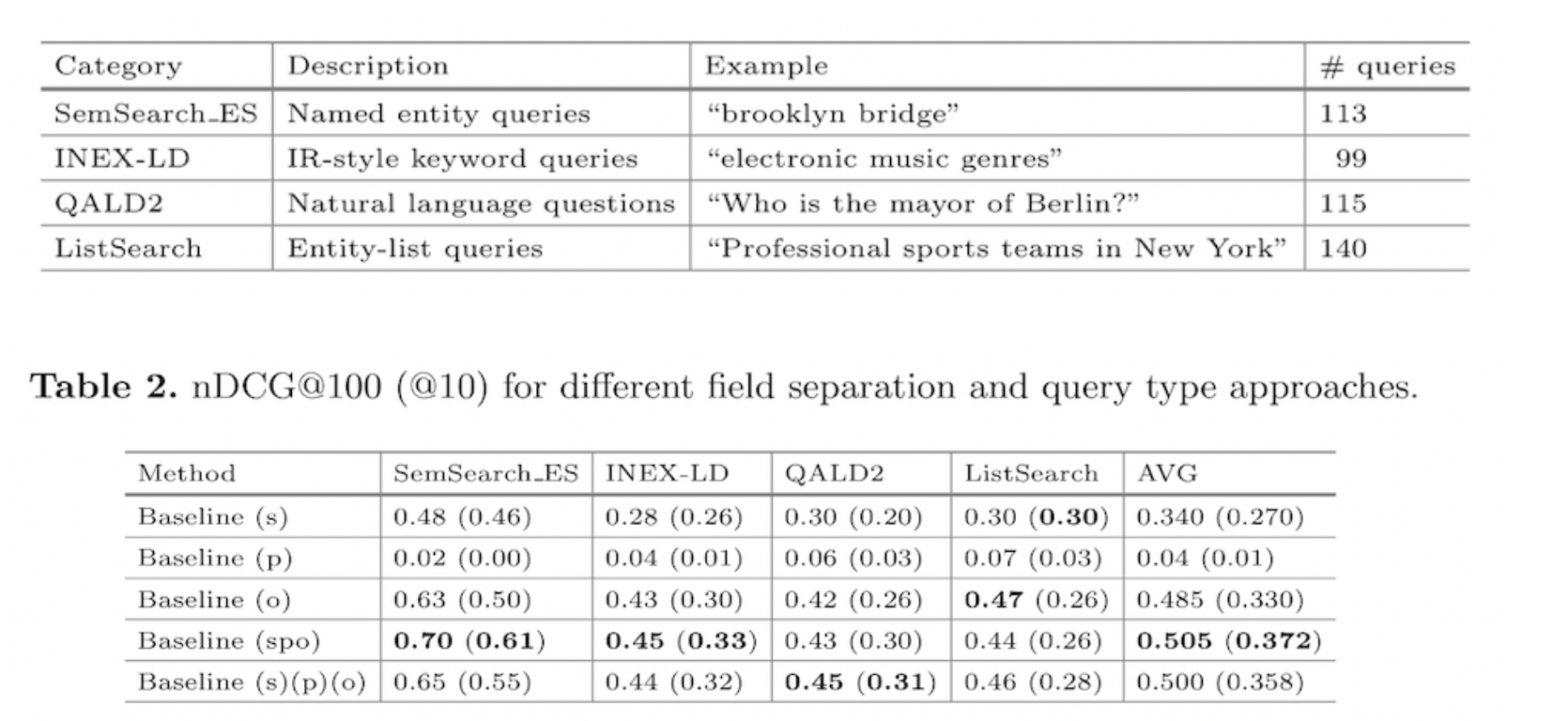
- field seperation : 어떤 필드를 대상으로 검색할지?

- field seperation: 여러 필드를 대상으로 검색하는 경우, 가중치를 어떻게 둘지?

- similarity model: 어떤 유사도 함수(=score)를 사용하여 정렬할지?

References
- Unsupervised Open-Domain Question Answering (2021)
- An Intelligent Question Answering System based on Power Knowledge Graph (2021)
- A Survey on Complex Question Answering over Knowledge Base: Recent Advances and Challenges (2021)
- Keyword Search over RDF: Is a Single Perspective Enough? (2020)
- Keywords Search over RDF Using Document-Centric Information Retrieval Systems (2020)
- Evolution of Techniques for Question Answering over Knowledge Base: A Survey (2020)
- A Survey of Question Answering over Knowledge Graph (2019)
- KBQA: Learning Question Answering over QA (2019)
- Sanity Check: A Strong Alignment and Information Retrieval Baseline for Question Answering (2018)
- Core Techniques of Question Answering Systems over Knowledge Bases: a Survey (2018)
- A literature review on question answering techniques, paradigms and systems (2018)
- Survey on Challenges of Question Answering in the Semantic Web (2017)
- Semantic Parsing via Staged Query Graph Generation: Question Answering with Knowledge Base (2015)
- Information Extraction over Structured Data: Question Answering with Freebase (2014)
반응형
'논문리뷰' 카테고리의 다른 글
| Revealing the Myth of Higher-Order Inference in Coreference Resolution (0) | 2021.12.26 |
|---|---|
| Detecting bursty terms in computer science research (0) | 2021.12.25 |
| DKN: Deep Knowledge-Aware Network for News Recommendation (0) | 2021.12.24 |
| Political Ideology Detection Using Recursive Neural Networks (0) | 2021.12.23 |
| MIND: A Large-scale Dataset for News Recommendation (0) | 2021.12.22 |