2021. 12. 25. 20:32ㆍ논문리뷰
이머징 이슈를 측정하는 방식으로 ‘term burstiness’를 공부해보기로 했다. term burstiness를 다룬 논문은 여럿 있는데, 그 중에서도 이 연구가 향후 bursty해질 term을 ‘예측’한다는 관점에서 설명이 가장 잘 되어있는 것 같다. 이머징 이슈에서는 어떤 주제가 bursty해질 것인가에 대한 ‘예측’이 핵심이라고 생각한다.
Abstract
Research topics rise and fall in popularity over time, some more swiftly than others. The fastest rising topics are typically called bursts; for example “deep learning”, “internet of things” and “big data”. Being able to automatically detect and track bursty terms in the literature could give insight into how scientific thought evolves over time. In this paper, we take a trend detection algorithm from stock market analysis and apply it to over 30 years of computer science research abstracts, treating the prevalence of each term in the dataset like the price of a stock. Unlike previous work in this domain, we use the free text of abstracts and titles, resulting in a finer-grained analysis. We report a list of bursty terms, and then use historical data to build a classifier to predict whether they will rise or fall in popularity in the future, obtaining accuracy in the region of 80%. The proposed methodology can be applied to any time-ordered collection of text to yield past and present bursty terms and predict their probable fate.
Ⅰ. Burst Detection 선행연구
1.1 LDA 계열: 토픽(term의 집합)의 시작점을 찾고, 변화 양상을 살펴보는 모델
- 말뭉치를 시간에 따라 조각으로 나누고, 각 조각에 LDA를 적용해 토픽을 도출. 그 다음 기간 별로 유사도 계산을 통해 토픽을 연결하고, 토픽의 시계열적 변화를 관찰.
- 토픽의 시간에 따른 변화를 보면서, bursty해지는 구간도 발견 가능.
- 한계: interpretability 낮음. 일관성 있게 기간별 토픽을 연결하는 것이 어려움.
1.2 Kleinberg 계열: busrty terms를 먼저 찾고, 이들을 그룹지어 토픽을 도출하는 모델
- Kleinberg(2002)의 burst detection algorithm은 문서의 단어들이 non-bursty state와 busrty state를 반복한다고 가정. 이 알고리즘을 트위터, 뉴스 등에 적용한 다양한 후속 연구 존재.
- 그러나, scientific litereature의 경우 Klenberg의 가정과는 달리 문서가 연속적으로 생성되지 않고 ‘batch’로 생성됨.(예: 저널 발간 주기) 트위터나 뉴스처럼 초 단위가 아니라, 일, 월, 년 등 더 긴 단위의 time step을 사용할 필요가 있음.
- 또한, scientific literature의 경우 기간에 따라 corpus의 특성과 내용이 매우 달라지는 특성을 가짐.
Ⅱ. Moving Average Convergence Divergence(MACD)
2.1. EMA(Exponential Moving Average)
SME(Simple Moving Average)가 시계열적 데이터의 노이즈를 줄이기 위해, 과거 값들을 동일한 가중치로 평균하는 것이라면, EMA는 최신 값에 가중치를 두어 과거값들을 평균한다. 즉, 최신의 정보를 더 많이 반영하는 것이다. EMA에 대한 자세한 내용은 아래 동영상에 잘 설명되어 있다.
https://www.youtube.com/watch?v=lAq96T8FkTw
https://youtube.com/watch?v=NxTFlzBjS-4&feature=youtu.be
2.2. MACD
- Moving Average는 수렴(Convergence)하고 발산(Divergence)하는 특징이 있다. 예를 들어, 1년 기준 장기 이동평균과, 1주일 기준 단기 이동평균이 있을 때, 1주일 이동평균선이 1년 이동평균선에서 멀어지는 경우, 지난 1주일의 추세가 1년의 추세와 다르게 나타나는 발산이 나타난다. 반대로, 1주일 이동평균선이 1년 이동평균선과 가까워지는 경우 지난 1주일의 추세는 1년의 추세와 유사하게 수렴한다고 할 수 있다. 이러한 Moving Average의 Convergence와 Divergence를 분석하기 위한 방법이 MACD이다.
- MACD는 (1) MACD선, (2) Signal선, (3) MACD선과 Signal 사이의 차이를 나타내는 히스토그램 세 가지 요소로 구성된다.(참고)

- MACD: 단기 EMA - 장기 EMA. 단기 추세와 장기 추세 사이의 차이를 나타냄. MACD > 0 이면 단기적으로 장기 추세에 비해 상승세에 있는 것이고, MACD < 0 이면 단기적으로 장기 추세에 비해 하락세에 있는 것.
- Signal: MACD에 다시 EMA를 취한 것. 단기 추세와 장기 추세의 차이의 이동평균.
- 히스토그램: MACD - Signal. MACD와 Signal의 교차점은, MACD의 단기 EMA와 장기 EMA 교차점보다 빠르게 나타나는 특성이 있음.
- 관련 선행연구인 He and Parker(2010)은 MACD를 사용하여, PubMed에서 나타나는 MeSH(Medical Subject headings) terms의 발생 빈도를 계산함. 그러나 이 연구에서는 vocabulary를 한정시키지 않고 문서 전체에 등장하는 단어에 대해 MACD를 적용.

- Burstiness 수식의 의미: 분자는 MACD-Signal의 값인 historam을 의미. 즉, MACD가 Signal보다 얼마나 큰지(=단기 추세가 장기 추세보다 얼마나 상승세인지)를 의미. 분모는 단어별로 histogram의 폭이 다양하기 때문에 정규화 시킨 것. 분모 값으로 평균, 중앙값, 최댓값 등을 실험하였으나, 최댓값에 루트를 취했을 때 가장 안정적인 값을 보여서 채택.
2.3 Predicting the future prevalence of terms using MACD features
- burstiness metric을 바탕으로, bursty term을 정의하고 busrty term을 예측하는 실험을 진행. 다음의 5 단계로 이루어짐.
- 예측 시점 이전의 20년치 term frequency 데이터를 가져온다.
- 20년치 데이터에 burstiness metric을 적용하여, burstiness threshold를 넘는 후보 단어들을 고른다.
- 후보 단어들의 MACD, 히스토그램 등 각종 통계값을 활용하여 feature를 생성한다.
- 예측시점부터 I(interval) 사이에 예측시점보다 burstiness가 높아지는지, 적어지는지를 label로 삼는다.
- feature(term frequency의 시계열적 특성)를 통해 label(현재 기준으로 bursty해지는지 아닌지)을 예측하는 모델을 만든다. -> RandomForest 사용
- 아래와 같이, 몇 년도 뒤의 term burstiness를 대상으로 할 것인지, burstiness가 얼마 이상인 term을 가지고 학습을 진행할 것인지에 대해 비교 실험 진행.

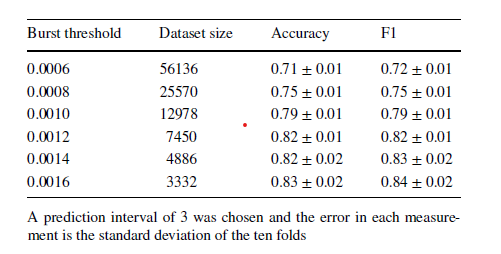
- 현재에 비해 더 bursty해질 것으로 예상된 단어와 그렇지 않은 단어는 다음과 같다.

2.4 DTM을 사용한 토픽 clustering
- DTM을 사용하여 단어 특성을 포함하고, clustering 실시하여 bursty term들을 주제별로 묶어서 분석을 진행했다.
느낀점
- 단어의 등장빈도의 시계열적 통계값만 독립변수로 사용했는데 단어 임베딩을 함께 사용한다면 성능이 올라갈까?
- 만약 단어 임베딩을 사용한다면, 모든 연도의 데이터를 한 번에 넣어서 학습해야 한다. 연도 별로 별도로 하면 다른 벡터 공간에 임베딩 되기 때문이다.
- 그러나 모든 연도를 넣는 경우 연도별 특성을 반영하지 못하게 된다. 중요한 단어만 연도 suffix를 붙이는 것은 어떨지?
'논문리뷰' 카테고리의 다른 글
| QA system 관련 논문 리뷰 (0) | 2021.12.28 |
|---|---|
| Revealing the Myth of Higher-Order Inference in Coreference Resolution (0) | 2021.12.26 |
| DKN: Deep Knowledge-Aware Network for News Recommendation (0) | 2021.12.24 |
| Political Ideology Detection Using Recursive Neural Networks (0) | 2021.12.23 |
| MIND: A Large-scale Dataset for News Recommendation (0) | 2021.12.22 |