2021. 12. 24. 20:30ㆍ논문리뷰
‘Pop Your Filter Bubble’ 프로젝트를 진행하면서 DKN: Deep Knowledge-Aware Network for News Recommendation 논문을 리뷰하게 되었다. 뉴스의 내용을 반영한 추천을 위해 네트워크 분석이 유용할 것이라고 생각했다. 논조는 결국 단어의 관계에 의해 형성되기 때문이다.
Abstract
Online news recommender system aim to address the information explosion of news and make personalized recommendation for users. In general, news language is highly condensed, full of knowledge entities and common sense. However, existing methods are unaware of such external knowledge and cannot fully discover latent knowledge-level connections among news. The recommended results for a user are consequently limited to simple patterns and cannot be extended reasonably. To solve the above problem, in this paper, we propose a deep knowledge-aware network (DKN) that incorporates knowledge graph representation into news recommendation. DKN is a content-based deep recommendation framework for click-through rate prediction. The key component of DKN is a multi-channel and word-entity-aligned knowledge-aware convolutional neural network (KCNN) that fuses semantic-level and knowledge-level representations of news. KCNN treats words and entities as multiple channels, and explicitly keeps their alignment relationship during convolution. In addition, to address users’ diverse interests, we also design an attention module in DKN to dynamically aggregate a user’s history with respect to current candidate news. Through extensive experiments on a real online news platform, we demonstrate that DKN achieves substantial gains over state-of-the-art deep recommendation models.
I. Introduction
- 뉴스 기사 추천의 특징
- 뉴스는 다른 컨텐츠(음악, 영화, 식당 등)에 비해 highly time-sensitive하고, 단기간에 가치가 떨어진다. 따라서 전통적인 CF가 덜 유용할 수 있다.
- 사람들은 다양한 특정 토픽들에 관심을 갖기에, 이 토픽들의 관계를 다면적으로 반영하여 다음 컨텐츠를 추천하는 것이 중요하다.
- 뉴스의 언어는 많은 매우 압축적이며, 많은 knowlege entity와 맥락을 가진다. 예를 들어, ‘Boris Johnson Has Warned Donald Trump To Stick To The Iran Nuclear Deal’ 이라는 기사 제목은 ‘Boris Johnson’, ‘Donald Trump’, ‘Iran’, ‘Nuclear’라는 엔티티를 가진다. 또한 이 기사는 ‘North Korean EMP Attack Would Cause Mass U.S. Starvation, Says Congressional Report’라는 기사와 비슷한 맥락을 공유하는데, co-occurence나 clustering에 주로 근거하는 기존의 contents-based 방식은 이러한 latent knowledge-level connection을 포착하기 어렵다. 기사들 사이의 내재적 관계를 찾기 위해 knowledge graph를 활용하는 것이 도움될 수 있다.
- DKN(deep knowledge-aware network)은 CTR(click-through rate) prediction을 위한 contents-based 모델이다. 유저의 클릭 기록을 인풋으로 받아, 다른 기사에 대한 예상 클릭 확률을 계산한다. 먼저, 인풋으로 들어온 뉴스 기사의 단어들을 knowledge graph의 엔티티와 매칭시킨다. 더 나아가 각 단어의 이웃 엔티티를 통해 contextual entities도 반영한다. 이것을 사용하여 KCNN(knowledge-aware convolutional neural networks)을 통해 word-level과 knowledge-level의 reepresentation을 통해 임베딩을 학습시킨다.
- KCNN의 특징
- multi-channel: 컬러 이미지 CNN처럼, word embedding, entity embedding, contextual entity embedding의 세 가지 채널을 쌓아 뉴스 기사의 정보를 추출한다.
- word-entity-aligned: word와 entity의 쌍이 인식된다. (‘Donald Trump’ - ‘Person’ 이라는 매칭 관계가 반영)
- KCNN을 통해 뉴스 기사에 대한 knowledge-aware graph embedding을 얻는다.
- candidate 기사를 쿼리로 유저의 클릭 어텐션을 적용하여 유저의 과거 클릭 기록을 통합한 정보를 얻는다. 이를 사용하여 CTR 예측을 진행한다.
II. Preliminaries
2.1 Knowledge Graph Embedding
- graph embedding: 네트워크의 entity-relation-entity triplet (h, r, t) 구조 정보를 담을 수 있도록 entity와 relation을 저차원 벡터로 표현하는 것
- translation-based models, tensor-factorization-based models, neural network-based model로 구분할 수 있는데, 이 논문에서 소개하는 translation-based model 위주로 정리해보았다. (참고: A Survey on Knowledge Graph Embedding: Approaches, Applications and Benchmarks, 관련 블로그 글)
- translation-based-models
- 아래 소개한 4가지 방식 모두 (h, r, t)의 triplet에 대하여 h와 t가 비슷한 경우에는 거리가 가깝게, h와 t가 상이한 경우에는 거리가 멀게 임베딩하는 것이 목표이다.
- h + r ≈ t : h에 r을 더하면 t가 되는 관계를 가정
- 이를 위해 주로 margin-based hinge ranking loss function을 minimize한다.
 margin based ranking loss
margin based ranking loss
- 실제로 연결관계가 없는 엔티티(correct triplets) 사이의 거리 f(h’, t’)는 실제로 연결관계가 있는 엔티티 사이의 거리(incorrect triplets) f(h, t)에 마진(λ)을 더한 것보다 커야한다. 반대의 경우에 loss=0이 되어 업데이트가 일어나지 않는다.
- 엔티티 사이의 거리를 측정하는 함수 f(h, t)를 score function이라고 하며, score function을 어떻게 정의하는지에 따라 그래프 임베딩 방식이 구분되는 것이다.
 (a) TransE (b) TransH (c) TransR (d) TransD
(a) TransE (b) TransH (c) TransR (d) TransD
- TransE
- 가장 기본적인 모델. 다면적관계를 표현하기 어렵다. h와 t가 동일한 엔티티더라도 다양한 r을 가질 수 있는데 모든 관계가 같은 하이퍼플레인에 표현되므로 한계가 존재한다.
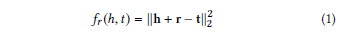 TransE score function
TransE score function - TransH
- TransE의 한계를 보완하기 위해 relation-specific 하이퍼플레인에 h벡터와 t벡터를 투영한다. 관계에 따라 다른 하이퍼플레인에서 score function을 계산하므로 transE에 비해 다면적 관계를 표현할 수 있다.
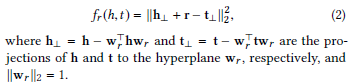 TransH score function
TransH score function - TransR
- TransH의 score function에서 entity와 relation을 같은 차원에 존재하는 반면, TransR은 entity와 relation은 특징이 다르므로 다른 차원에 존재해야 한다고 본다. 이에 따라 h와 t를 엔티티 차원에서 릴레이션 차원으로 선형변환하여 릴레이션 차원에서 score function을 계산한다.
 TransR score function
TransR score function - TransD
- TransR에서 h와 r이 relation 차원으로 선형변환될 때 동일한 transform matrix를 공유하는 것에 비해, TransD는 각 엔티티와 릴레이션을 모두 고려한 transfrom matrix를 제시한다. 엔티티의 상이한 특성을 반영한 transform matrix가 필요하다는 것이다.
 TransD score function
TransD score function
2.2 CNN for Sentence Representation Learning

문장의 n개 단어를 d차원의 벡터로 표현하여, nxd 매트릭스로 표현하고, 이에 dxl 크기의 필터를 적용한 후 풀링하여 각 피처맵을 concat한 문장 임베딩을 만든다.
3. Problem Formulation
- 유저의 클릭 기록과 각 기사 제목의 제목 엔티티들간의 관계를 사용하여 유저가 다음으로 클릭할 기사를 예측하는 것이 목표이다.
4. Deep Knowledge-Aware Network
4.1 DKN Framework
- 각 유저가 클릭했던 기사들과 추천 후보 기사 1개를 인풋으로 받아 KCNN으로 기사에 대한 네트워크 임베딩 생성
- 후보 기사를 쿼리로 유저 클릭기록에 어텐션 취하고 가중합으로 aggregate해서 유저별 임베딩 생성
- 1개 후보 기사에 대한 그래프 임베딩과 유저임베딩을 concat하여 DNN을 통해 해당 유저가 그 기사를 볼 확률을 계산

4.2 Knowledge Distillation
- entity 임베딩
- entity linking: 문장에서 엔티티를 찾아내어 지식그래프와 연결하는 자연어처리 태스크
- knowledge graph construction: 1 hop 내외의 관계를 모두 연결해서 sub-graph를 확장
- knowledge graph embedding
- entity embedding

- entity context 임베딩
- 엔티티의 주변 맥락을 반영하기 위해 연결된 엔티티들의 평균을 내어 해당 엔티티의 context 임베딩으로 사용. “Fight Club” 엔티티의 임베딩만 사용하는 것이 아니라, 이와 연결된 “Brad Fitt”, “Suspense”의 임베딩을 평균낸 context 임베딩도 함꼐 활용하는 것.
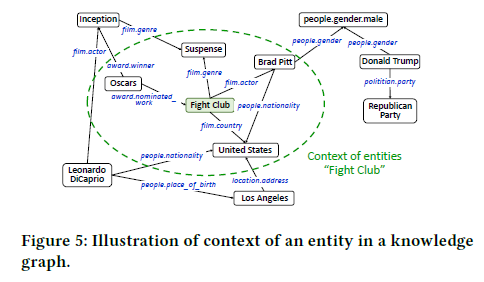 주변 엔티티 임베딩을 평균내어 context 임베딩을 구한다.
주변 엔티티 임베딩을 평균내어 context 임베딩을 구한다. 
4.3 Knowledge-aware CNN
- 단어 임베딩과 엔티티 임베딩을 어떻게 합치는지가 문제가 된다. 가장 간단한 것은 각 문장에 대해 단어 임베딩, entity 임베딩, entity-context 임베딩을 모두 concat하여 문장 임베딩으로 사용하는 것이지만 다음과 같은 한계가 있다.
- concat 하는 경우 단어와 entity가 쌍으로 연결되는 관계(alignment)를 고려하지 못한다.
- 단어와 엔티티는 서로 다른 방식으로 임베딩되었기에 같은 차원(dimension)에 놓고 생각하는게 적절하지 않을 수 있다.
- 따라서 단어 임베딩, entity 임베딩, entity-context 임베딩을 채널로 쌓아서 CNN을 적용하는 multi-channel and word-entity-alinged KCNN을 제안한다.
- entity 임베딩과 entity-context 임베딩을 각자의 차원에 두고 이를 단어 임베딩 차원으로 변환시키는 transformation matrix를 적용한다.
 transformation은 선형일 수도 있고 비선형일 수도 있다.
transformation은 선형일 수도 있고 비선형일 수도 있다.
- 문장의 각 단어를 (단어 임베딩, entity 임베딩, entity-context 임베딩)의 3가지 차원으로 나타낸다. 컬러 이미지와 같이 각 단어가 3개의 채널을 가지는 것이다.

- 채널에 대해 필터와, 맥스풀링을 차례대로 진행하고, 필터 개수 만큼의 피쳐맵을 concat하여 제목(input)에 대한 최종 임베딩을 얻는다
4.4 Attention-based User Interest Extraction
- 유저에 대한 최종 임베딩은 클릭 기록 임베딩의 가중합으로 결정
- 가중합을 위한 가중치는 인풋으로 들어온 후보 기사 제목과 클릭 기록의 기사 제목들 간의 어텐션으로 구한다.


- 최종적으로 후보 기사의 KCNN 임베딩과 유저의 임베딩을 DNN에 넣어서 candidate 기사에 대한 클릭 확률을 구한다.
5. Experiments
5.1 Dataset Description
- Bing News의 기사 제목 사용(141,487명의 유저, 535,145개의 기사)
- 2016.8.16 ~ 2016.6.11까지를 train set, 2017.6.12~2017.8.11까지를 test set으로 사용
5.2 Baselines / 5.3 Experiment Setup / 5.4 Results

baseline과의 비교 결과

DKN 튜닝 비교 결과
5.5 Case Study

실제 샘플 유저가 읽은 것과 예측 결과

네트워크 임베딩을 포함했을 때, 비슷한 기사끼리 attention이 잘 적용되는 것을 확인
5.6 Parameter Sensitivity

단어 임베딩 차원, 엔티티 임베딩 차원, 필터 개수, 윈도우 사이즈 변화에 따른 결과 비교
'논문리뷰' 카테고리의 다른 글
| QA system 관련 논문 리뷰 (0) | 2021.12.28 |
|---|---|
| Revealing the Myth of Higher-Order Inference in Coreference Resolution (0) | 2021.12.26 |
| Detecting bursty terms in computer science research (0) | 2021.12.25 |
| Political Ideology Detection Using Recursive Neural Networks (0) | 2021.12.23 |
| MIND: A Large-scale Dataset for News Recommendation (0) | 2021.12.22 |